
세리프 따라잡기
알고리즘에 대해, 정렬 알고리즘 본문

1. 알고리즘 소개
알고리즘이란 '문제를 해결하는 절차'
- 알고리즘의 조건(입력, 출력, 유한성, 명백성, 효과성)을 만족해야 한다. [모든 명령은 실행 가능한 형태여야 한다.]
- 알고리즘은 분석을 통해 좋고 나쁨을 평가할 수 있다. [ex. 정렬 알고리즘에서 막무가내로 정렬한다면..? X]
- 알고리즘은 기초 프로그래밍(c언어)과 자료구조를 공부한 후에 배우면 좋다
- 알고리즘은 논리이며 수학이고 실질적인 개발에 적용되는 기초적인 아이디어이다.
-1. 알고리즘이 쓰이는 곳
'개발'의 전체 과정에 사용된다.
- 실제 프로그램을 개발할 때 효율적인 알고리즘을 적용함으로써 원하는 결과를 도출
- 스케줄 관리 프로그램: 달력에서 특정한 달에 해당하는 일 수는 어떻게 구하는지?
- 내비게이션 프로그램: 여러 개의 중간 지점을 거쳐서 특정 지점으로 갈 때 가장 빠른 길은 무엇? [대표적 다익스트라, 플로이드-워셜 알고리즘 등]
- 게시판 프로그램: 한 페이지당 게시글을 10개씩 출력해야 할 때 어떻게 출력? [페이징 알고리즘]
-2. 알고리즘 공부 이유
- 세계적으로 알고리즘에 관련된 대회 및 기관이 많다. 대표적으로 ACM-ICPC, 구글 코드잼, 코드포스, 정보올림피아드 등이 존재
- 일반적인 개발을 할 때 높은 난이도의 알고리즘은 거의 사용되지 않는다. [ex. 실무에서 버그를 끈기있게 해결하는 자세가 더 중요] 그럼에도 문제 해결 능력을 보기 위해 어려운 알고리즘 문제를 푸는 연습을 함.
- 알고리즘 문제가 종합적인 개발 역량을 평가하기에 가장 좋은 용도를 갖음.
-3. 공부 강의
-4. 언어
C 언어와 기본적으로 거의 동일한 C++을 이용.
C와 C++의 차이는 class가 있고 없고의 차이 정도! 작은 시스템이며 기계에서 빨리 작동하는 등 대부분 거의 동일.
2. 정렬
-1. 선택 정렬 (select sort)
문제
= 1 10 5 8 7 6 4 3 2 9
가장 작은 것을 선택해서 제일 앞으로 보내기를 반복한다면, 결과적으로 계속 반복되어 1 2 3 4 … 10 으로 정렬이 된다.
문제풀이는 → 선택 정렬 문제는 10 * (10 + 1) / 2 = 55번의 수행을 반복해 결과 도출.
n * (n + 1) / 2 == O(n * n) → 빅오표기법(Big O)
즉, 선택 정렬의 시간 복잡도는 O(n^2)이다. = 다른 정렬 알고리즘과 비교했을 때 비효율적 알고리즘 중 하나
-2. 버블 정렬 (bubble sort) 문제 예시
선택 정렬과 같이 몹시 직관적인 해결 방법. 바로 옆의 두 숫자끼리 비교해 더 작은 숫자를 앞으로 보내주는 것을 반복. 즉, 옆에 있는 값과 비교하여 더 작은 값을 반복적으로 앞으로 보내는 정렬 방법.
정렬 알고리즘 중에서 구현은 가장 쉽지만 가장 비효율적인 알고리즘. [ 가장 느림 ]
버블 정렬의 시간 복잡도는 선택 정렬과 같지만, 작동 시간(실제 수행 시간)이 더 걸리는 이유는 옆과의 비교를 계속 자리를 바꾸는 연산을 하기 때문에 컴퓨터가 해줘야 할 작업의 양이 많아서.
-3. 삽입 정렬(insertion sort) 문제 예시
각 숫자를 적절한 위치에 삽입하는 방법으로 해결. 이전의 정렬 방식들이 무조건 위치를 바꾸는 방식이었다면, 삽입 정렬은 '필요할 때만' 위치를 바꿈. 항상 왼쪽에 있는 것이 정렬이 되었다고 가정하기 때문에 당장 자신이 왼쪽에 있는 것보다 크다면 멈춘다. [멈출 포인트를 알기에 이전의 선택/버블 방식보다 효율적]
삽입 정렬은 비교적 느린 정렬 알고리즘에 속하지만(시간 복잡도 선택/버블과 같음), 쉽게 생각할 수 없는 조금 복잡한 구조를 가지고 있음.
EX. 2 3 4 5 6 7 8 9 10 1
다음의 예시와 같이 데이터가 '거의 정렬된' 상태라면 가장 효율적인 알고리즘에 속한다. 이후에 배울 퀵, 힙, 병합 정렬 등 보다 더 빠르거나 동일한 수준으로 빠르게 정렬을 수행한다.
-4. 퀵 정렬(quick sort) 문제 예시
대표적인 빠른 알고리즘이 바로 퀵 정렬 알고리즘. '분할 정복(특정한 배열이 있을 때 그 배열을 반복적으로 분할. 즉 배열의 원소들을 나누어서 계산)' 알고리즘으로 평균 속도가 O(N * logN)이지만, 항상 보장할 수는 없다. 퀵 정렬의 최악 시간 복잡도는 O(N^2)이다. 이 경우는 이미 정렬이 되어있거나, 거의 정렬된 상태라면 일어난다. = 정렬할 데이터의 특성에 따라 적절한 정렬 알고리즘을 사용하는 것이 중요!
퀵 정렬은 특정한 값을 기준으로 큰 숫자와 작은 숫자를 서로 교환한 뒤에 배열을 반으로 나눈다(두 집합으로 나눔). 퀵 정렬에는 '기준 값(피벗: pivot)'이 있음.
추가 문제: 퀵 정렬 소스 코드에서 단 두 부분만 바꾸어서 내림차순 정렬 소스 코드로 바꾸어보기
while(i <= j){ //16번 줄 코드
while(i <= end && data[i] >= data[key]){ // 큰 값을 찾는 위치와 작은 값을 찾는 위치만 바꿔주면 내림차순으로 바꿀 수 있다.
i++;
}
while(j > start && data[j] <= data[key]){
j--;
}
-5. 병합 정렬(merge sort) 문제 예시
퀵 정렬은 피벗 값에 따라 편향되게 분할될 가능성이 있고 최악의 경우 시간 복잡도가 O(N^2)이 되는 반면, 병렬 정렬은 정확히 반으로 나누기 때문에 최악의 경우에도 O(N * logN)을 보장. [퀵 정렬의 한계점을 보완해줌 but, 퀵 정렬보다 빠른 건 아님!]
하나의 큰 문제를 두 개의 작은 문제로 분할한 뒤에 각자 계산하고 나중에 합치는 방법을 채택. 퀵 정렬과 다르게 피벗 값이 없고 항상 반으로 나눈다는 특징을 갖고 있다.
문제 예시 = 7 6 5 8 3 5 9 1

→ 합치는 순간 정렬을 수행
병합 정렬을 구현할 때 신경써야 할 부분: 반드시 정렬에 사용되는 배열은 '전역 변수'로 선언해야 한다는 것. 그렇지 않다면 함수 안에서 매 번 배열을 선언해야 하기 때문에 메모리 자원의 낭비가 매우 커짐 = 기존의 데이터를 담을 추가적인 배열 공간이 필요 = 메모리 활용이 비효율적이라는 문제!
-6. C++ STL sort() 함수 다루기1 / 문법에 대해
정렬 같은 경우 이미 오래전부터 연구가 되었기 때문에 정렬과 관련한 좋은 라이브러리가 이미 존재 = 매번 정렬 알고리즘을 구현할 필요가 전혀 없다 = C++ STL sort()를 사용해 구현해보기. standard template library
-6.1 sort() 함수의 기본 사용법 문제
-6.2 sort() 함수의 기본 사용법2 문제
-6.3 데이터를 묶어서 정렬하는 방법 [실무 적합] 문제
-7. C++ STL sort() 함수 다루기2
-7.1 벡터 & 페어(pair) 라이브러리 사용법
문제1와 같이 소스코드의 길이를 짧게 해주는 기법을 숏코딩(short coding)이라 함. 작성한 소스코드의 시간 복잡도(효율성)가 동일하다면, 프로그래밍 대회에서는 소스코드가 짧을 수록 남들보다 앞설 수 있다! [STL을 많이 알고 활용할 수록 알고리즘 대회에서 좋은 성적을 낼 수 있음]
벡터(vector) STL은 마치 배열과 같이 작동하는데 원소를 선택적으로 삽입(push) 및 삭제(pop)을 할 수 있다. 즉 단순한 배열을 보다 사용하기 쉽게 개편한 자료구조라고 할 수 있다. = 소스 코드를 획기적으로 단축.
-7.2 페어 이중으로 겹쳐 사용: 문제2
-8. 힙 정렬(heap sort)
힙 정렬은 앞서 배운 병합 정렬, 퀵 정렬만큼 빠른 정렬 알고리즘이며 O(N * logN)이 나오는 정렬 알고리즘이다. 힙 정렬은 정렬 자체로도 의미가 있으나, 후에 고급 프로그래밍 기법으로 갈 수록 자주 등장하기 때문에 개념을 잘 알아야 한다.
힙 정렬 = 힙 트리 구조(heap tree structure)를 이용하는 정렬 방법.
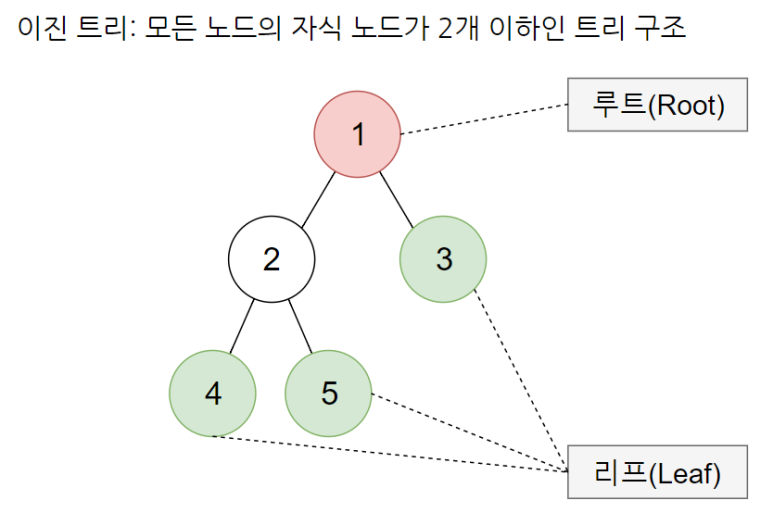
- 이진 트리(binary tree): 컴퓨터가 데이터를 표현할 때 데이터를 두 개씩 이어 붙이는 구조(노드:node)를 말한다. 모든 노드의 자식 노드가 2개 이하인 트리 구조. [트리: 데이터가 서로 연결되었다는 것]
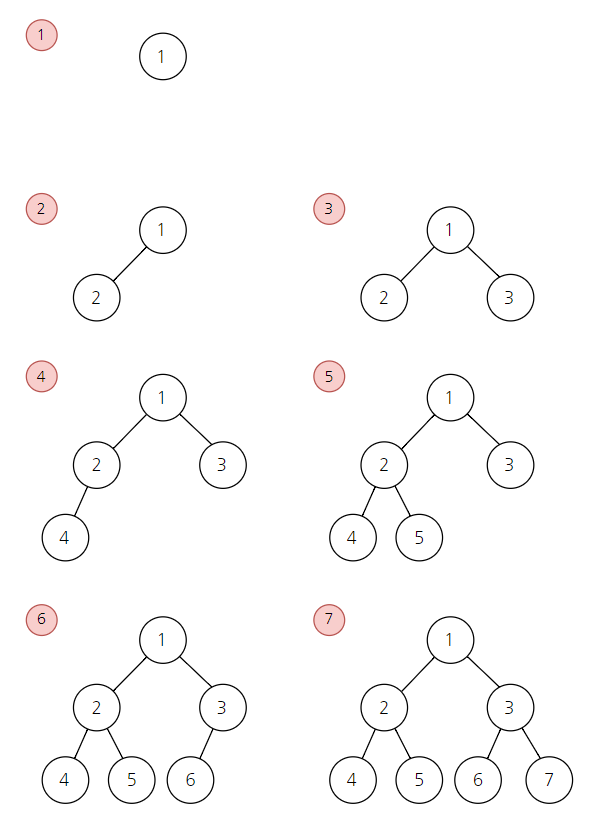
- 완전 이진 트리: 데이터가 좌·우로 차근차근 들어가는 구조. 즉 이진 트리의 노드가 중간에 비어있지 않고 빽빽하게 가득 찬 구조를 뜻함.
- 힙은 최솟값이나 최댓값을 빠르게 찾아내기 위해 완전 이진 트리를 기반으로 하는 트리. 최대 힙과 최소 힙이 존재. [최대 힙은 '부모 노드'가 '자식 노드'보다 큰 힙 = 즉, 더 큰 값이 부모가 됨(위로 감)]

- 힙 생성 알고리즘(heapify algorithm)
특정 노드에 의해 최대 힙이 붕괴되는 경우가 있다. 아래와 같은 상황.

11 5 8을 보면 최대힙이 생성되었는데, 5 7 4를 보면 붕괴되었다. 이럴 경우에 정렬을 수행하기 위해 사용되는 것이 힙 생성 알고리즘이다. 힙 생성 알고리즘은 '단 하나의 노드'에 대해 수행하며 '하나의 노드를 제외하고 나머지가 최대 힙에 부합하다'는 가정하에 쓰인다. 위와 같은 예시가 대표적: 5와 7의 자리를 바꿔 최대 힙 구조가 되게 수행해준다.
이후로도 자식 중에 자신보다 더 큰 자식이 있다면, 자신(부모)과 위치를 바꿔 최대 힙 구조를 만들어준다.

heapify 시간 복잡도: 한 번 자식 노드로 내려갈 때마다 노드의 갯수가 2배씩 증가한다는 점에서 O(logN), 사실상 모든 데이터를 기준으로 힙 생성 알고리즘을 쓰지 않아도 되어서 O(N)에 가까운 속도를 낼 수 있다.
즉, 힙 정렬은 추가적인 배열이 필요하지 않아 메모리 측면에서 병합 정렬보다 효율적. 또한 항상 O(N * logN)을 보장함. 이론적으로 퀵, 병합 정렬보다 더 우위에 있으나 단순 속도면으로는 퀵 정렬이 더 빠르기에 힙 정렬이 일반적으로 많이 사용되지는 않는다.
